今回はPythonでのスクレイピング活用についてまとめます。
Python, 自動化って言葉をよく耳にするがどう活用できるものか…?
スクレイピングってなんかスゴそうではあるものの、初心者には無理なのでは…?
pythonをかじりはじめると、テキストマイニングとともによく目にするスクレイピング。
これはどういうものなのか?そしてどうやれば簡単に出来るのか?
最近、ここもかじってみたところ、私のような初心者でもサクッと出来るものであったので備忘録としてまとめます。
Pythonでもっと効率化・自動化したい!という初心者の方の一助になれば幸いです(‘ω’)ノ

今回の論点整理
さて、今回ですがSeleniumライブラリを使ったスクレイピングを行い
「認証が必要なページにログインして必要なデータを取得する」
ということを実現させます。
これが実現できることで、各種アフィリエイトの実績など、ウェブ上で毎日確認をしにいくような作業が一気にまとめて行えます。
例えば、ブログをやっている人であればAmazonアソシエイトやA8などの結果をピックアップすることなども簡単にできます。
毎日、ID・パスワードを入力して読み込んで一つずつ確認する手間が省けるのは想像以上にストレスフリーです。
また、今後もクラウド上でデータを管理していくことが増えることを考えると、APIの利活用と併せてスクレイピングをマスターしておくと、他でも転用できそうです。
そのため、今回は下記のポイント3点について述べていきます。
- スクレイピングとは
- Seleniumを使ったコード
- Seleniumを活用した具体例
順に触れていきます。
スクレイピングのポイント
スクレイピングとは
まず結論から言うと、スクレイピングとは “データを収集した上で利用しやすく加工すること” を意味します。
具体的には、指定のWEBページを参照し、必要な箇所を指定することで、簡易的に情報をコピペして抽出することが出来る機能です。
似たような意味合いでクローリングという言葉もありますが、こちらは“Web上を巡回すること”を意味します。
具体的には、Googleなどの検索まどから複数のページを検索して条件の合うWEBページのHP情報を取得して閲覧することを繰り返す(巡回する)ことを行います。
そのため、このスクレイピングとクローラーは似たような文脈で出ることが多いのですが、セットで使われる場合などもあるのでここの定義は整理しておく必要があります。
- スクレイピング
▷特定のHPから特定の情報のみ取得 - クローリング
▷Webサイトを巡回してHP情報を複数取得
また、作成したファイルを自動で起動させたり、取得したデータを、csvファイルで吐き出したり、google スプレッドシートなどに吐き出したりすると自動化への道が一気に広がります。
そのため、まずは最初の第一歩として、このスクレイピングなるものを下記で示します。

自動化の技術を身に着けるためにスクレイピングの技術は必須ですね。
Seleniumを使ったコード
では、次に実際のスクレイピングについて言及します。
今回扱うのはSeleniumですが、これは前述したスクレイピング・クローリングともに簡単に実装できるものです。
そのため、まずは下記のようにpythonにインストールするところから進めます。
pip install seleniumその後に、今回扱うのは下記のライブラリになります。
from selenium import webdriver
from time import sleepこのwebdriverというのはブラウザをプログラムで操作をする際に使うライブラリです。
各ブラウザで操作をする方法が個別にあるようですが、最も扱いやすいのがGoogle Chromeを扱うChromeDriverのため今回はこれを使います。
以下のリンクからChromeDriverをダウンロードして設定を行います。
使い方は、ダウンロードした後ZIPファイルを解凍して、chromedriver.exeを指定の場所に置き、パスを通します。
具体的には下記のようなコードで指定をします。
driver = webdriver.Chrome('ChromeDriverのディレクトリ + chromedriver')例えば、私の場合、Cドライブの直下に”Test”フォルダを作成してその中にDriverを置きましたので、下記のような記載になります。
driver = webdriver.Chrome('C:\Test\chromedriver_win32\chromedriver')以上がSeleniumを使うための準備です。
次に使い方ですが、大きくは下記の3つを行えばスクレイピング完了です。
- URLを指定する
- 要素を取得する
- 要素を出力する
①においてはdriver.get()というお手軽関数が容易されているため、この関数を使います。
②については色々なやり方がありますが基本的にどのページであってもChrome上で右クリックをして「検証」というボタンを押せば閲覧できて指定できます。
③はcsvやスプレッドシート連携などのライブラリを使えば出来ます。
尚、これらの詳細はググれば色々と解説サイトが出てきて分かります。
例えば下記のようなサイトなどが詳細まで記載されていて分かりやすいです。
ただ、私のような初心者が一番早くて学習効率が良かったのがUdemyの動画講座でした。
私が参考にした下記のものですが、細かいところまで解説してくれておりすぐに真似て応用ができました。

動画でやり方を追う方が細かい設定部分まで網羅されていてかつ齟齬がないね。
Seleniumを活用した具体例
では、上記を踏まえて、具体的にどんなことが出来るのか?
今回はブログを運営している人であれば気になるであろうアフィリエイト実績の確認についてです。
Google AdsenseであればGoogle Analyticsに連携が容易にできますが、それ以外の実績は都度、確認しに行く必要があり手間でしかないです。
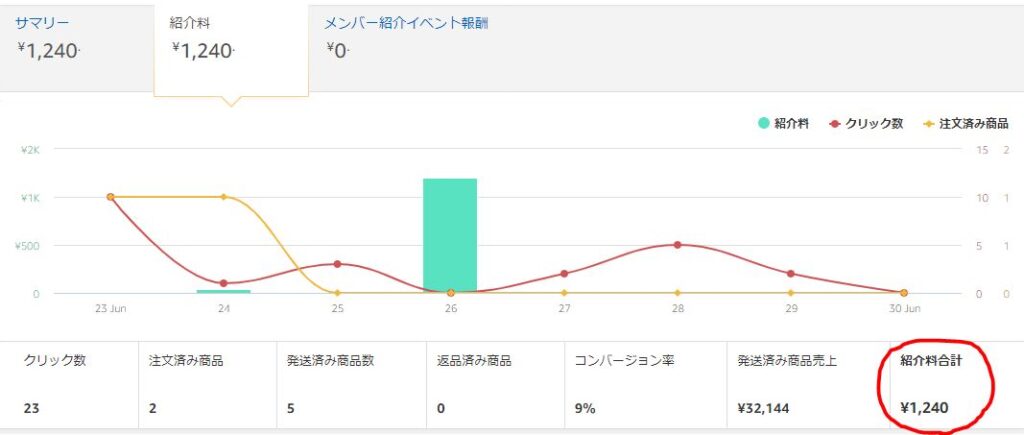
そのため、これらの情報をウェブ上から自動的に拾うプログラムの一例としてAmazonアソシエイトから実績データを引き抜くコードを記載しました。
自動取得のプログラム
今回はPythonで指定ページの指定箇所(紹介料合計)を抽出するスクレイピングのプログラムを作ります。
下記のコードを部分修正して実行すれば基本的にOKです。
from selenium import webdriver
from time import sleep
#ドライバーとID・パスの設定
driver = webdriver.Chrome("★自身のdriver保存場所 C:\Test\chromedriver_win32\chromedriver")
USERNAME = "★自身のログインID"
PASSWORD = "★自身のログインパス"
#Amazonアソシエイトのページの指定
target_url = "https://www.amazon.co.jp/ap/signin?openid.return_to=https%3A%2F%2Faffiliate.amazon.co.jp%2Fhome&openid.identity=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.assoc_handle=amzn_associates_jp&openid.mode=checkid_setup&marketPlaceId=A1VC38T7YXB528&openid.claimed_id=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0%2Fidentifier_select&openid.ns=http%3A%2F%2Fspecs.openid.net%2Fauth%2F2.0&openid.pape.max_auth_age=0"
driver.get(target_url)
sleep(1)
error_flg = False
#ページのログイン認証
try:
username_input = driver.find_element_by_xpath("//input[@name='email']")
username_input.send_keys(USERNAME)
sleep(1)
password_input = driver.find_element_by_xpath("//input[@name='password']")
password_input.send_keys(PASSWORD)
sleep(1)
login_burron = driver.find_element_by_xpath("//input[@type='submit']")
login_burron.submit()
sleep(1)
#レポートの詳細の確認
move_button = driver.find_element_by_xpath("//a[@data-assoc-eid='ac-home-view-report-link']")
move_button.click()
sleep(1)
#合計金額の部分を指定して抽出
money = driver.find_element_by_xpath("//div[@id='ac-report-commission-commision-total']")
print(money.text)
sleep(2)
except Exception:
error_flg = True
print("Amazonのユーザー名、パスワード入力時にエラーが発生しました。")
#ヘッダーを付けてデータフレーム化しCSV出力
import pandas as pd
import csv
num=[money.text]
header = ["Amazon"]
df = pd.DataFrame({'成果':num},index=header)
df.to_csv("Test.csv",encoding="shift_jis")
#Webdriverを閉じる
driver.close()- 位置指定
▷★driverを保存した場所の指定 - ID指定
▷★AmazonのログインIDを記載 - パス指定
▷★Amazonのログインパスを記載
基本的には上記3つを書き換えれば実行できるはずです。
今回はcsvファイルで該当データだけが入ったものをアウトプットをしましたが、複数選んだり、インデックス名とカラム名を変更するなどして拡張は可能です。
また、今回はAmazonの紹介料のページだけ引き抜きましたが、当然他のページにも拡張可能です。
ではこちらのサイトであればどういうコードになるか?などの拡張させる点については前述のUdemy動画などを見ると応用が出来ます。

一連の流れを一度作ってしまえば自力で拡張することは簡単です。
まとめ

今回ポイントしてまとめてきたのは以下の3点です。
- スクレイピングとは
▷指定のHPから必要な情報を抽出する技術 - Seleniumを使ったコード
▷GoogleChrome上のwebdriverを動かすコードで簡単実装 - Seleniumを活用した具体例
▷Amazon アソシエイトを試しに実行してcsv出力
上記を順に追っていけば、簡単に自分の時間の使い方が見える化できます。
普段使っている現状の時間の活動状況が見えると、ムダ時間を排除するために必要なことが考えられます。
そして何と言っても凄まじいのが、なんと全部無料!ということです。
これはデータ分析が好き嫌い関わらず、だれもが覚えておくべき内容だと思います。
今後も大量データ社会になることは間違いないので、身近なところからデータを整理して自分で分析する習慣を共に作っていきましょう(‘ω’)ノ
ご精読頂きありがとうございました!
m(_ _)m
その他、Python初心者のお勉強のお供
上記の内容と併せて実務で活かすという視点では下記の参考図書も合わせて確認すると理解が深まります(-_-)