


今回は“AI,機械学習の位置づけ”について理解を深めます。
統計を勉強する中で、「AI、機械学習、深層学習」というものが色々なところで出てきますがこれらはどのような関係性なのでしょうか。
AIという言葉は日常でよく出てきますが、上記を正確に説明せよ。といわれると、ウッ…と止まってしまったりします。
そのため、今回は言葉の定義をしっかりと整理するために主に上記の3点について整理します。
ビビっときたTipsや手帳術を発信します ٩( ᐛ )و
●資格:国家資格キャリアコンサルタント
●実績:手帳歴18年 | 自作歴10年| デジプラ歴2年
●属性:30代2児の父 | 7つの習慣の資格も保有
目次
今回の論点整理

”AI/機械学習/深層学習“の位置づけ
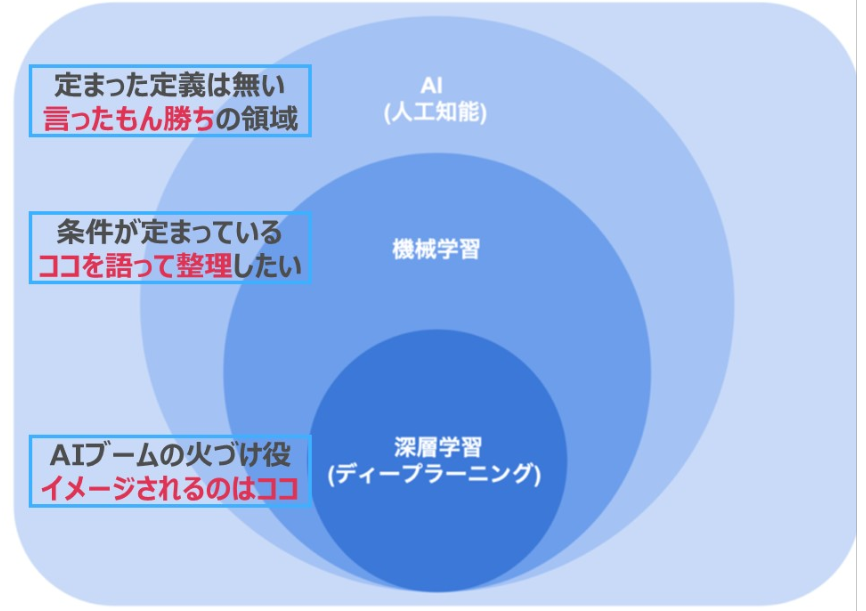
AI、機械学習、深層学習を説明すると以下のような位置づけになります。
この手の話が議題に上がる時多くの場合は、「とりあえずAIが全てを解決してくれる」、「今の時代、AIだろう」みたいな感じで抽象論が繰り広げられるケースが多い気がします。
その上で、議論する人それぞれの認識・定義がバラバラになっており、議論が収束するどころかかみ合わないままに進むことが問題な気がします。
そのため、この手の話の位置づけと言葉の定義を整理するべく、下記に俯瞰した視点で少しまとめます。今回は下記のような状況を想定します。
具体的な想定場面
状況:経営層から呼び出され”今後はAIで何とかせぃ!そもそもお前のとこで何が出来るんだ?”と問われる
意図:AI、機械学習の定義から整理した上で地に足ついた納得度の高い打ち手を説明したい
このような時、「機械学習、AI」という考え方を抑えておく必要があると思います。
以下はこれらの用語知識を使う際に思い出すべき点を、後で振り返れるようにポイントを絞って備忘録としてまとめます。
今回の抑えドコ
そこで、今回は上記を実現する手順について下記に備忘録的にまとめたいと思います。
- 今回の焦点
▷AI,機械学習の概念・定義に関して
(想定場面:企画をする中で何となくAIという言葉が飛び交っている) - ポイント
▷AIの位置づけとは
▷機械学習とは何か
▷深層学習とは何か
”AI/機械学習”理解のポイント
ポイント① AIの位置づけとは

まずAIという言葉でなんでもござれという感じです。そもそもAIとは何かさすのか。これは
の省略です。つまり人口の知能ということになります。それでは次に、このAIは何を以ってAIとするかの定義するのか。これは
というのが実際です。つまり、曖昧な広義な意味で使われており、高度な技術でなくとも機械が判断する要因が少しでもあれば自動だろうがなんだろうがウソにはならないということです。
つまり、『使ったもん勝ち』という事実を知っておくことが大事な気がします。
そのため、最新の人型ロボットみたいなAIど真ん中な内容でなくとも、身の回りにあるパソコンもスマホも見方によってはAIといっても広義の意味では別にウソにはなりません。
なので、新企画を使う時にAIがAIが、というのは間違ってはおらず、ITを使おう、デジタルを使おうといったそんなニュアンス・抽象レベルのものと捉えておけば混乱は少ないと思います。
そのため、この手の話をする際は、ある程度定義ができる2つ目の機械学習の概念理解が肝になってくると思います。
ポイント②機械学習とは何か
機械学習は簡単にいうと「実際のデータを元に機械が自動で判断する」方法になります。
そのため、感覚的ですが、”AI”と言われた時にもつ具体的なイメージの恐らくこの機械学習の領域であることが多い気がします。
そのため前提として判断の根拠となる「データ」が必要不可欠であり、それを元に計算式を元に算出します。ちなみにこの機械学習は以下の3つに大別されます。
- 教師あり学習
- 教師なし学習
- 強化学習
順番に触れます。
教師あり学習
教師あり学習では、コンピューターに「入力」と「正しい出力」が紐づいた学習データを与え、ある入力を受けたときに正しい出力を返せるアルゴリズムを構築する学習方法です。
例えばこの分類の中には以下のようなものがあります。
▽回帰問題
回帰問題とは、出力が実際の値であるものを言います。(”総数/売上”など)連続出力内で結果を予測し、入力変数をいくつかの連続関数に出力します。
詳しくは以下に回帰問題(回帰分析)についてポイントを整理しています。

▽分類問題
分類問題とは、出力がカテゴリであるものを言います。(”赤/青/緑”あるいは”買った/買わない”など)結果を離散出力で予測します。
詳しくは以下に分類問題についてポイントを整理しています。

教師なし学習
教師なし学習では、コンピューターには「入力」データのみを与え、データの中に内在するパターンなどをコンピューターが独自で抽出します。
例えばこの分類の中には以下のようなものがあります。
▽クラスタリング
クラスタリングは、データに内在するグループ分けを見つけ出します。

ここまでが機械学習の基本形です。さらに少し別概念な第3勢力が強化学習です。
強化学習
上記の学習はあくまで目的としてセットしたデータの「実際の結果に基づいて算出する」ことに対し、強化学習はとある環境下で目的としてセットされた「報酬(スコア)を最大化させる行動」を学習します。
例えば、歩行ロボットなどは、報酬として「歩けた距離」をセットされ、実際の実験データからそれが最大化させる学習をしていきます。
以上、大まかな機械学習のカテゴリでした。
▽プチまとめ
上記からAI・AI言われる時はこれら3つの学習タイプにあわせてどれに該当するのかを考えながら議論をすると現実的な地に足ついた議論になるはずです。
また、さらに一歩踏み込んだもので深層学習(ディープラーニング)というものもあるので、こちらもあわせて概念を理解できていると理解が進むため、下記も合わせてご確認ください。
ポイント③深層学習とは何か

AIと言われた時に真っ先に思い浮かぶ「先鋭的な分析」のイメージは恐らくこの領域かと思います。AIブームの火付け役になった経緯もあります。
深層学習(ディープラーニング)とは変数自体をシステムが試行錯誤しながら最適化する手法です。そのため、上記で紹介したものとの違いは特徴量を手動でセットするか、機械におまかせするか、です。
ちなみに、機械学習は入力条件のセットの仕方には言及はないため、この深層学習は対になるものではなく部分集合になります。
具体的にいうと構造化データが基本であったところに、色々な変数の作り方・手法を用いて非構造化データでも利用が可能という点が大きな特徴です。
ちなみに構造化データと非構造化データとは以下のようなイメージです。
- 構造化データ:
エクセルのように表データとしてまとまっているもの - 非構造化データ:
画像や音声のようにきれいなデータとしてまとめられないもの
これを実現する方法はニューラルネットワークという手法を用いますが、結果的に画像処理や自然言語、また音声など、一見分析無理では?と思われるものまで分析可能です。
詳しくは以下に画像処理と自然言語処理についてポイントを整理しています。


まとめ
理解しておくべきポイントは以下3点でした。
- ポイント①:AIの位置づけとは
▷AIはいったもんガチ、まずは機械学習を語れるように - ポイント②:機械学習とは何か
▷教師あり・教師なし・強化学習の3カテゴリがベース - ポイント③:深層学習とは何か
▷機械が特徴量(説明変数)を自動的に算出するもの
上記で触れた通り、一番大事になるのは
ということを理解した上で、話をすることが最重要な気がします。
その上で、「できるのか、できないのか」の話になった際、機械学習/深層学習を定義して、技術的にデータ的に可能・不可能を語るのがよいのかと思います。
そもそも、この認識自体がバラバラになるケースが多いので、ここを整理しつつ議論が積み重なる風土を創るのがまずはやるべきことだと感じています。
ご精読頂きありがとうございました!
m(_ _)m
その他、統計基礎のお勉強のお供
上記の内容と併せて実務で活かすという視点では下記の参考図書も合わせて確認すると理解が深まります(-_-)



その他、統計初学者が抑えておきたい理解ポイント
実務での応用を考えると下記のポイントを抑えると実務につながりやすいと思うので合わせてご参照下さい(‘ω’)ノ
【統計基礎】データサイエンスにおける確率分布(ポアソン分布、正規分布等)とは
【統計基礎】分類問題における決定木やランダムフォレストの仕組とは
【統計基礎】クラスタリングにおけるk-meansやエルボーメソッドとは
【統計基礎】分析結果やモデル精度の解釈(決定係数, AUC, 混合行列等)とは
【統計基礎】ディープラーニング, 画像処理(プーリング等)とは
【統計基礎】自然言語処理、テキストマイニング、word2vecとは
【統計基礎】データサイエンスの知識整理 / AI, 機械学習, 深層学習の位置づけ
【統計基礎】経営に”データサイエンス風な報告”を求められた際の留意点
データサイエンスを網羅的にコスパ良く実践的に学びたい時はこちらもオススメ!
>>データミックス使って感じたメリット・デメリット























データサイエンスを網羅的にコスパ良く実践的に学びたい時はこちらもオススメ!
>>データミックス使って感じたメリット・デメリット