


今回はPythonでエクセルのピポットテーブル的なことを行います。
Pythonでデータ分析をしよう!と思った時に、実務レベルで考えると
エクセルにピポットテーブル的なこと(クロス集計)ができないものか?
と思う時が多々あります。結論からいうと、当然できる!話ですので、具体的な方法論・コードについて下記に触れます。
私のような非エンジニアの方がプログラミングをかじって自主勉強する際の参考になれば幸いです(‘◇’)ゞ

今回の論点整理

今回のアウトプット
前回エクセルデータを読み込むことは出来ました。今回はそのデータをいじくります。具体的には
と思ったので、やってみました。こんな感じになります。
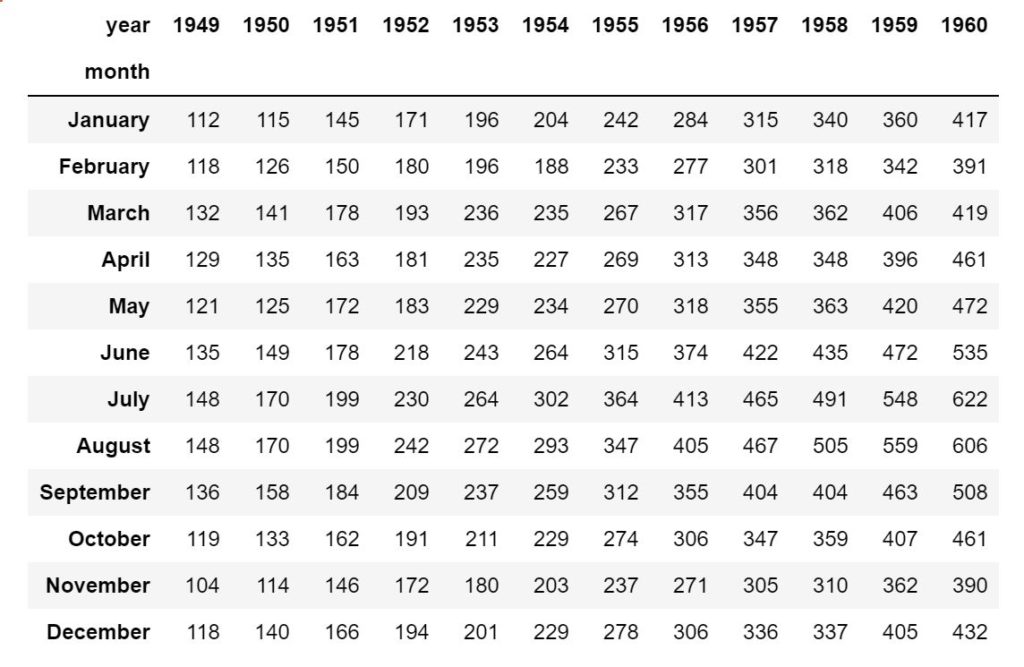
見た目が質素ですが、ピポットテーブル(クロス集計)になっています。尚今回はフリーのデータを用いた集計になります。
今回の抑えドコ
今回、上記を実現する手順について下記にポイントをまとめます。
順に触れていきます。
今回のポイント

①ピボットテーブルとは
ピボットテーブルは一言でいうとクロス集計を行うことです。さらにザックリ言うと
ということです。実はこの2軸で分析する(マトリクスを作る)というメリットは非常に多く、業務中に発生する「傾向を教えて」といわれるフワッと依頼の多くもこれで片付きます。
これはエクセルでは当たり前のように使っていると思いますが、pythonでも割と簡単に実現でき、コードで書くと以下です。
pd.pivot_table(○○, index='行に指定したいもの', columns='列に指定したいもの' ,values="値にしたいもの")はい、これだけです。
“pd”は前回ブログで説明したpandasというライブラリを利用しており、その中にpivot_tableというエクセルのそのまんまの機能が入っています。
尚、()内の引数は、指定のファイル名を書き、index(縦), columns(横)にそれぞれの設定したい軸を設定し、value(表の中の数字)を設定すれば完了です。
前回、エクセルデータの読み込みをまとめたので、それとセットで実施すればエクセルベースの資料を元にサクッとクロス集計できます。(コードは後述します)
記事を取得できませんでした。記事IDをご確認ください。
②フリーデータと軸の設定
さて、ここで考えたいのが、実際のデータを使う以前に例として使えるデータがないかです。
実はpythonにはこんな時に使えるフリーデータがあるのでこれを利用します。今回はseabornというライブラリを使います。(このライブラリの特徴・活用は次回まとめます)。
まず下記のコードを入力すると無料で使えるデータセットがどんなものがあるかを教えてくれます。
#フリーで使えるデータを参照
import seaborn as sns
sns.get_dataset_names()
-output-
['anscombe',
'attention',
'brain_networks',
'car_crashes',
'diamonds',
'dots',
'exercise',
'flights',
'fmri',
'gammas',
'geyser',
'iris',
'mpg',
'penguins',
'planets',
'tips',
'titanic']結果としてこれだけのデータセットが入っています。
今回はflights(飛行機の乗客者数の推移)を利用します。データを読み込む以下の形で簡易的なデータセットが読み込めます。
#flights データを読み込み
df_flights = sns.load_dataset('flights')
df_flights.head()
-output-
year month passengers
0 1949 January 112
1 1949 February 118
2 1949 March 132
3 1949 April 129
4 1949 May 121このデータを使って、前述したピボットテーブル(pd.pivot_table)を読み込み軸を設定すると以下の通りです。(df_fligts_pivotという関数に格納して出力します)
df_flights_pivot = pd.pivot_table(data=df_flights, values='passengers', columns='year', index='month')
Print(df_flights_pivot)これで、冒頭にあげたアウトプットの形になるはずです。
また、このpivot_tableですが、色々と軸の読み込ませ方があるようなので「python pivot_table ●●」で調べると理解が深まります。(例えば以下のような引数の設定など)
■ご参考記事:ピボットテーブルの使い方 (外部サイトに移動します)
#例1. 出力する値を変更する場合:aggfuncを活用(以下は最小値(np.min)を指定)
pd.pivot_table(df_flights, index='month', columns='year', values='passengers',aggfunc=np.min)
#例2. カテゴリごとの総計を算出する場合: 引数marginsを活用
pd.pivot_table(df_flights, index='month', columns='year', values='passengers', margins=True)
#例3. 行・列・値を複数指定する場合:引数の値を[](リスト型)で指定
pd.pivot_table(df_flights, index=['変数1', '変数2'], columns='変数3', values=['変数4', '変数5'])上記を元に、indexやcolumnsやvaluesをいじくりまわしながら、あーだこーだ、考えながら出力していくことで有力な仮説が見えてくると思います。
③表データの軸の拡張
さて、ここまできたらあともう一つやりたいことが出ると思います。それは何かというと
つまり、データセットをまたいで、データの列を拡張したいということです。
例えば、上記のflightsデータに下記のような簡易データを別立ててで作って読み込み、列としてつなげることを想定します。
まずは簡易データ(table)をPC上で作成しアップロードします。
#自作で日本語表記と降水量の表を作成
#尚、日本語で読み込む場合は文字化けするのでSHIFT-JISを指定
table= pd.read_csv('add_table.csv',encoding="SHIFT-JIS")
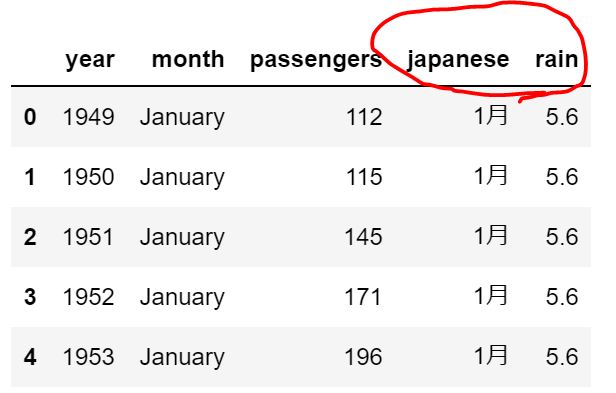
table.head()
-output-
month japanese rain
0 January 1月 5.6
1 February 2月 7.2
2 March 3月 10.6
3 April 4月 13.6
4 May 5月 20.0上記を元にflightsデータ(df_flights)と簡易データ(table)とを指定データ(month)をキーにしてくっつけます。
♯2つのデータを突合して新しいデータ(df_flight2)に入力
df_flights2 = pd.merge(df_flights,table, on='month', how='outer')これを実行すれば、無事データセットの拡張(エクセルのvlookup関数)が出来ました。
ちなみにこのmergeという関数もpandasの機能の一つですが、調べると色々と扱い方はあるので「python merge ●●」で検索すると色々と使い方が分かります。
■ご参考記事:pandasの使い方 (外部サイトに移動します)
クロス集計に関しての留意点

さて、今回”クロス集計“を扱いましたが、これはどんな時に役に立って、どんな効用があるのでしょうか。そして、そもそも業務でのデータ分析において必要なことはなんなんでしょうか。
- 分析=数字から何らかの傾向を把握するという文脈が多い。
- 大まかな傾向や仮説を立てることはクロス集計で対応可能。
- 多くの場合は細かい解析よりも大まかな概要把握が求められる。
そのため、あるべきデータ分析は”やりたいこと(要件)をしっかりと整理”した上で仮説をもちクロス集計を色々して傾向をつかむという流れかなと思っております。
つまり、やるべきことは『データを読み込むやり方』と、それを元に『データをクロス集計するやり方』であり、このやり方さえ押さえておけば後はどうとでもなります。
まとめ
今回の学習で抑えるべきポイントは以下の通りでした。
- 今回の焦点
▷データを読み込みピポットテーブル(クロス集計)を使う
(想定場面:表データから仮説を作る(傾向を掴む)場合) - ポイント
▷ピボットテーブルとは
▷フリーデータと軸の設定
▷表データの軸の拡張
ここで、pythonで読み込めるフリーデータを元にpivot_tableを組むと以下のようなコードになります。
import seaborn as sns
import pandas as pd
df_flights = sns.load_dataset('flights')
df_flights_pivot = pd.pivot_table(data=df_flights, values='passengers', columns='year', index='month')
print(df_flights_pivot)ただ、本質的には、やりたいことをしっかりと整理した上で、クロス集計を行い多くの仮説を立てることが最も求められる点かなと思っております。
そのため、現業を加味して地に足つけつつも、今後必要な分析知識をバランスよく学んでいくことが大事なんだろうなと思う今日この頃です。
ご精読頂きありがとうございました。
m(_ _)m
【参考】Python初心者のお勉強のお供
上記の内容と併せて実務で活かすという視点では下記の参考図書も合わせて確認すると理解が深まります(-_-)
▼オススメの参考書籍(Kindle)▼



【参考】Python初心者が抑えたいポイント集
Python(主にデータ分析・自動化)に関しては
下記に実践したポイントをまとめています。基本的にコピペするだけでそのまま使えます٩( ᐛ )و
業務効率化・自動化においてはGoogle Apps Scriptもセットで学ぶことをオススメ!
こちらもコピペしてすぐに使えます!

PythonとGoogle Apps Scriptどちらを深めようかを迷っていればこちら!













▷データを読み込みピポットテーブル(クロス集計)を使う
(想定場面:表データから仮説を作る(傾向を掴む)場合)
▷ピボットテーブルとは
▷フリーデータと軸の設定
▷表データの軸の拡張