


今回はTwitterを元にしたの“オープンデータの利活用”について理解を深めます。
テキストマイニングをかじりはじめると、真っ先にやりたいと思うのがTwitterのテキスト分析だったりしないでしょうか。
ただ、これを調べてみると、何やら登録が必要なようで、APIというものを理解しないといけないらしい…
よくわからんし、面倒そう…と、自分自身、動きが止まった上に、いざやってみるとなるとかなりの時間を奪われた経緯がございます。
そのため、今回はツイッターデータをいじれる状態になるべく、関連する知識の理解と必要な手順について整理します。
今回の論点整理

”Twitterデータ“の使いドコ
身近なツイートデータも実は素材として使えます。このデータを取得してテキストマイニング(ワードクラウド)でまとめると以下のような形になります。

APIが開放されている(オープンデータとして使える)データを使うとかなり分析の幅が広がります。
また、このAPIの活用(オープンデータの取り込み方)のお作法さえ理解すれば他にも転用がしやすいのでまとめます。
今回の抑えドコ
そこで、今回は上記を実現する手順について下記に備忘録的にまとめたいと思います。
”Twitterデータ”活用のポイント

ポイント①API開放とは
まずはツイート分析をするにあたり、切っても切りはなせないのがAPIです。
私自身はこんなレベルの認識でした。よく耳にはするものの、あまり調べてこなかったので定義についてまず押さえます。
ここで、APIとはなんぞやと技術的な面も含めて解説するページは数多くあります。ご参考記事(外部リンクに飛びます)
これからは、超ザックリ言うと
ということですか。
例えばTwitterはAPI開放していますので、PythonやRなどを用いて、然るべき設定をすればTwitterデータをタダで利用できますよ。ということです。
これは便利!身近な情報だしTwitterならば大量データにアクセスできるので、とりあえず試すしかない!ということでいじってみました。
ポイント②Tweetデータ取得の下準備
で、どうやればその設定が出来るか調べた結果、やるべきステップは以下の3つだということが分かりました。
- STEP1
▷TwitterAPI開発者としての登録・申請 - STEP2
▷アクセストークンのID発行 - STEP3
▷出てきたデータを元にコーディング
つまり、APIなるものを活用するには上記のトークンなるID発番が必要で、それが出来さえすれば、あとは色々と出てきたデータを調理が出来るようです。
で、このSTEP1なのですが、色々と調べたのですが、なんか書いてあることと実際の登録画面で違いがあったりします。
と感じつつも、このちぐはぐする原因がわかりました。おかしな要員はこれ。
つまり、2019年8月以前の記事は旧バージョンの設定方法なので、最新版の記事を探す必要があります。その後も、色々調べましたが下記のサイトが一番まとまっていました。
非常によくまとまっているので、この順にやっていれば迷うことはないと思います。
ただ、申請理由記入(英語表記)は唯一「うっ…」と手がとまってしまったのですが、ダメもとで回答を日本語で書いたところ問題なくいけました。
記の記事通りに進めればSTEP2のトークン発行まではサクッといけると思います。自分の管理アカウントを作るのと、トークン発行までやれば準備完了です。
ポイント③データの抽出と利活用
上記の①②が出来ればあとは活用です。手始めに自分のTweetデータを元にテキストマイニングを実践してみました。試した手法は以下の2つ。
- 形態素分析
- ワードクラウド
はい、どちらも既存のライブラリ読みだして誰かが作ったプログラムを動かすだけです。これもまた、ググればいくらでもでてきます。
特に、難しいことはないのですが、自分のIDを指定して、データがひきぬけると感動はひとしおです。
(ただ、価値のないツイートしかないと愕然とします…)
これでエビデンスはできたので、色々と思いつく限り、比較するなりビジュアライズするなり、やり方は無限大です。コードは以下の通り
#######データ抽出########
pip install tweepy
pip install requests_oauthlib
import tweepy
import datetime
import pandas as pd
import requests
from requests_oauthlib import OAuth1Session
## 認証処理
consumer_key = "自身が登録したID"
consumer_secret = "自身が登録したID"
access_token_key = "自身が登録したID"
access_token_secret = "自身が登録したID"
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token_key, access_token_secret)
api = tweepy.API(auth)
## 取得対象のスクリーンネーム
screen_name = 'nesitive'
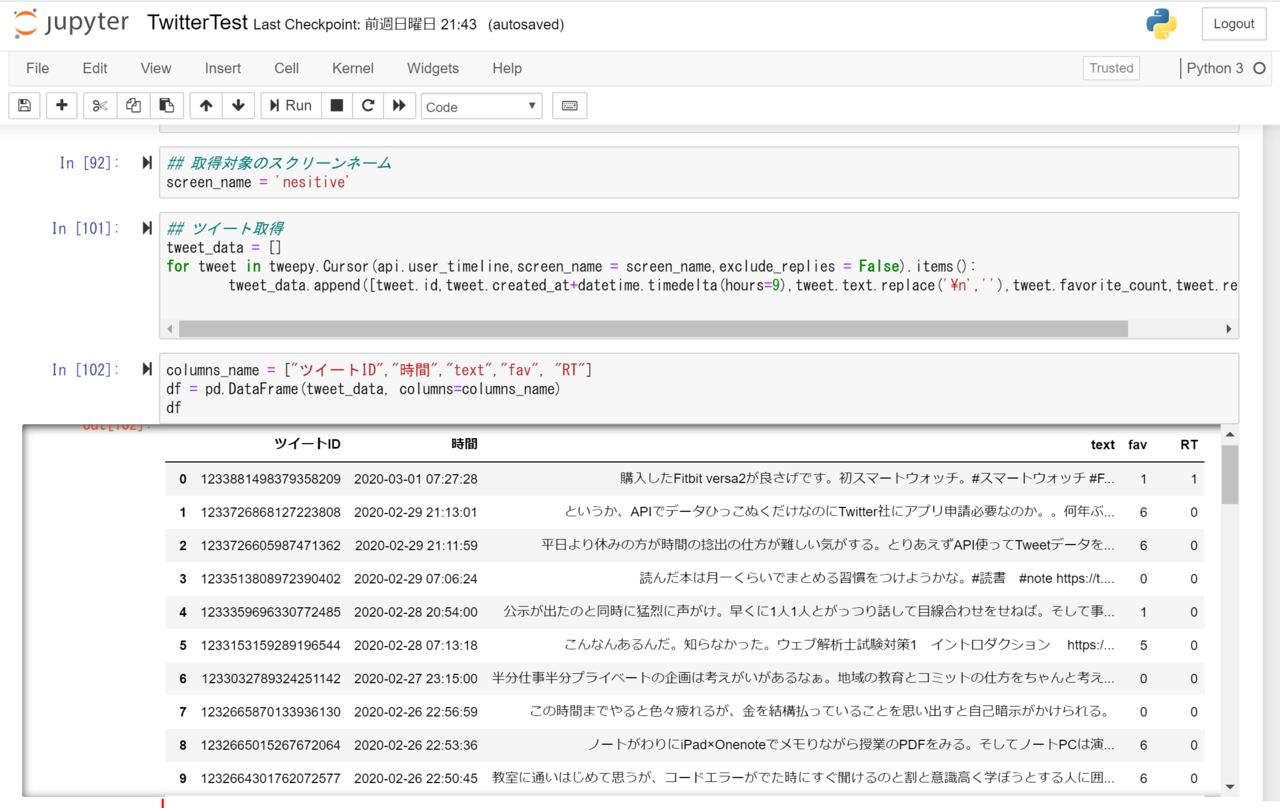
## ツイート取得
tweet_data = []
for tweet in tweepy.Cursor(api.user_timeline,screen_name = screen_name,exclude_replies = False).items():
tweet_data.append([tweet.id,tweet.created_at+datetime.timedelta(hours=9),tweet.text.replace('\n',''),tweet.favorite_count,tweet.retweet_count])
columns_name = ["ツイートID","時間","text","fav", "RT"]
df = pd.DataFrame(tweet_data, columns=columns_name)
df
# タイムライン取得用のURL
url = "https://api.twitter.com/1.1/statuses/user_timeline.json"
#パラメータの定義
params = {'screen_name':'nesitive',
'exclude_replies':True,
'include_rts':False,
'count':200}
#APIの認証
twitter = OAuth1Session(consumer_key, consumer_key_secret, access_token, access_token_secret)
#リクエストを投げる
res = twitter.get(url, params = params)あとは引き抜いたら上記のテキストマイニングの方法をとればよいだけです。
ちなみにテキストマイニングの手法理解は以下の通り

まとめ
上記を活用する際に、理解しておくべきポイントは以下3点
- ポイント①:API開放とは
▷API開放とは外部からデータベースにアクセス・連携可能という仕様であること - ポイント②:オープンデータ取得
▷更新時期に気を付けて実践してみた系のブログをまずはマネてみる - ポイント③:データ抽出と利活用
▷データ抽出した後にテキストマイニングを試みる
今回、外部記事をガンガン使いましたが、Pythonの素晴らしい所はネットで検索すればほぼやりたいことはヒットするという点です。
今回のようなオープンデータの利活用においてもTwitterデータ×テキストマイニングで検索するだけでかなりの数ヒットしますし、無料で時短で学べます。
素人だけど色々とデータ分析など、妄想したことを手軽に実践してみたいという方にはオススメです。
ご精読頂きありがとうございました。
m(_ _)m
【参考】Python初心者のお勉強のお供
上記の内容と併せて実務で活かすという視点では下記の参考図書も合わせて確認すると理解が深まります(-_-)
▼オススメの参考書籍(Kindle)▼



【参考】Python初心者が抑えたいポイント集
Python(主にデータ分析・自動化)に関しては
下記に実践したポイントをまとめています。基本的にコピペするだけでそのまま使えます٩( ᐛ )و

業務効率化・自動化においてはGoogle Apps Scriptもセットで学ぶことをオススメ!
こちらもコピペしてすぐに使えます!

PythonとGoogle Apps Scriptどちらを深めようかを迷っていればこちら!














▷SNSを介したテキストマイニングに関して
(想定場面:企業のマーケティングを担当している)
▷APIの開放とは
▷オープンデータ取得
▷データ抽出と利活用