


今回はPythonによる”データの可視化”について言及します。
Pythonでデータ分析をしよう!と思った時に、実務レベルで考えると
綺麗なグラフってそれっぽい見た目で魅せられないか?
と思う時が多々あります。結論からいうと、当然できる!話ですので、具体的な方法論・コードについて下記に触れます。
私のような非エンジニアの方がプログラミングをかじって自主勉強する際の参考になれば幸いです(‘◇’)ゞ

今回の論点整理

今回のアウトプット
今回は以下のように多くの視点で分析が視覚化できるようになりたいと思います。
分析の見た目は報告する際には最重要になると思うので意図したアウトプットをどのように出せばいいかの感覚をざっくりつかむためにそれぞれ視覚化の方法についてまとめます。
ただ、一つ一つをきりとると、簡易的なコード一行だけだったりするので全く難しくないです。
今回の抑えドコ
そこで、今回は上記を実現する手順について下記に備忘録的にまとめたいと思います。
ポイントを順に触れていきます。
今回のポイント

①視覚化の必要性
まず、最初に考えたいのが分析結果の「見た目」についてです。つまり、どうビジュアライズさせるか。という視点です。
個人的に、上司に分析結果を報告する際は特に、分析内容以上に分析結果の見た目が大事だと感じています。(本質的ではないことは重々承知の上で)
「伝え方が9割」という有名な本がありますが、意思決定者に一瞬で感覚的に良さを理解してもらわない限り、どんなに良いことをしても苦労が水の泡になるのが実際のビジネスだと思います。
ではどうやって視覚化するか?例えば代表的なところでいうと以下のようなものがあります。
▽ヒストグラム
要は、棒グラフ的なやつです。エクセルのグラフ化で一番最初にでる、最もシンプルなやつですね。棒グラフをカッコイイ表現にしたらヒストグラムになった程度に抑えればよい気がします。
▽箱ひげ図
あまり聞きなれないですが、各値の密度・分布も考慮したグラフです。どこにどれだけデータが密集していて平均値はあてになるのか?など数字の意味付けを直感的にできます(ちなみに最近は高校の教科書にも出てきます)。
▽クロス分析
前回まとめた、ピポットテーブル的な分析(クロス集計)のことです。2軸を組み合わせて分析できるメリットが非常に大きいのですが、可視化させるには少しコツが必要そうです。(後述します)
上にいくほど直感的に良さが理解でき、下に行くほど説明力が上がる気がします。これらを踏まえて、次から実際のデータ(フリーデータ)を元に、グラフ化の方法を考えます。
②matplotlab, seabornとは?
ここで、グラフのビジュアライズさせる際に使いたいライブラリがmatplotlab, seabornになります。
前者がいわば可視化ツールの基本セットで、後者が見た目を更に映えさせるための応用版というような位置づけかと思います。
例えば、下準備は以下のように読み込みます。
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np #数式を取り扱う際に読み込むライブラリ
iris = sns.load_dataset('iris') #フリーデータiris読み込み尚、このフリーデータの読み込み部分(sns.load.dataset部)については前回触れていますのでそちらをご参照ください。

さて、データを読み込んだら後は色々と試すのみです。下記に5点の可視化をしてみます。
- ヒストラグラムを並べる
- 散布図を一覧で一覧化する
- 折れ線グラフを記載する
- 箱ひげ図を表示する
- グラフを組み合わせる
以下、順に触れます。
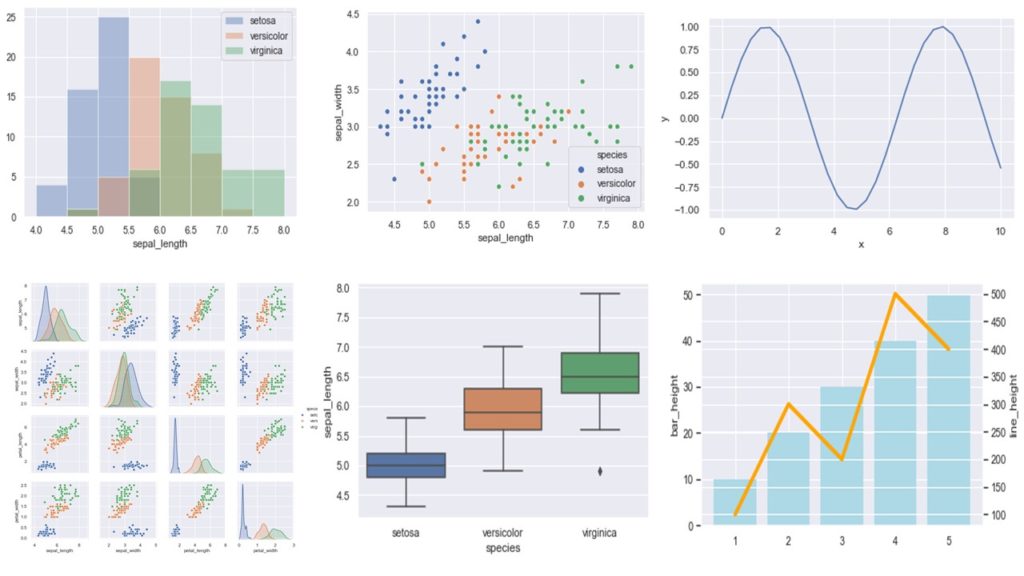
▽①ヒストグラムを並べるのは以下の通り
#各変数ごとにヒストグラムを重ねます。
sns.distplot(iris.query('species=="setosa"').sepal_length, kde=False, bins=np.linspace(4,8,9), label="setosa")
sns.distplot(iris.query('species=="versicolor"').sepal_length, kde=False, bins=np.linspace(4,8,9), label="versicolor")
sns.distplot(iris.query('species=="virginica"').sepal_length, kde=False, bins=np.linspace(4,8,9), label="virginica")
plt.legend()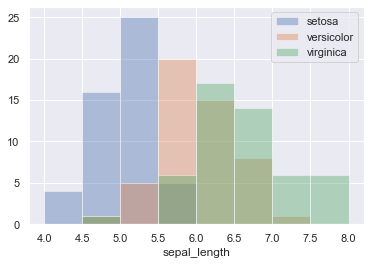
▽②散布図を一覧で一覧化するは以下の通り
#変数を指定してマッピングします。
sns.scatterplot(x='sepal_length', y='sepal_width', hue='species', data=iris)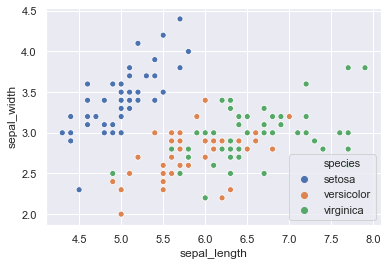
▽③折れ線・関数グラフを記載するは以下の通り
# x,yを指定してプロットしてグラフ化します。
x = [100, 200, 300, 400, 500, 600]
y = [10, 20, 30, 50, 80, 130]
plt.plot(x, y);
#三角関数などを入力することも可能
x = list(np.linspace(0,10,30))
y = list(np.sin(x))
sin = pd.DataFrame(list(zip(x,y)), columns=['x','y'])
sns.lineplot(x="x", y="y", data=sin)
▽④箱ひげ図を表示するは以下の通り
#変数を指定して箱ひげ図を並べます
sns.boxplot(x='species', y='sepal_length', data=iris)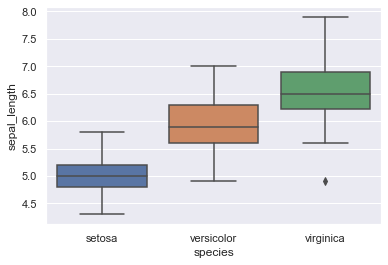
▽⑤グラフを組み合わせるは以下の通り
time = np.array([1, 2, 3, 4, 5])
bar_height = np.array([10, 20, 30, 40, 50])
line_height = np.array([100, 300, 200, 500, 400])
# 棒グラフを出力
fig, a1 = plt.subplots()
a1.bar(time, bar_height, align="center", color="lightblue", linewidth=0)
a1.set_ylabel('bar_height')
# 折れ線グラフを出力
a2 = a1.twinx()
a2.plot(time, line_height, linewidth=4, color="orange")
a2.set_ylabel('line_height')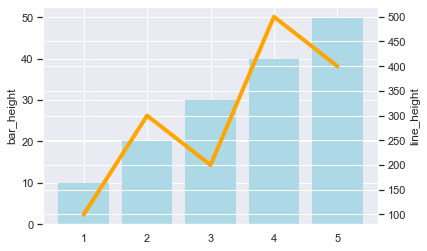
③ヒートマップ, ggpairsとは?
そして最後に考えたいのが、クロス集計の可視化についてです。
前回も伝えた通り、個人的に「見やすくかつ、説明力がある」最も実務で使いやすい分析はクロス集計だと思っているので、この視点での可視化は最重要だと思っています。
そこで、使える手段は大きくは二つ
- heatmap:表に色をつけて感覚的に分かるようにする
- ggpairs:2軸の組み合わせを全て一覧化する
順に触れます。
まず、前回のピボットテーブルの読み込みで扱った時と同じコード(旅客気の数字)を使ってヒートマップを作成します。
#飛行機の推移
import seaborn as sns
import pandas as pd
df_flights = sns.load_dataset('flights')
df_flights_pivot = pd.pivot_table(df_flights, values='passengers', columns='year', index='month')
sns.heatmap(df_flights_pivot)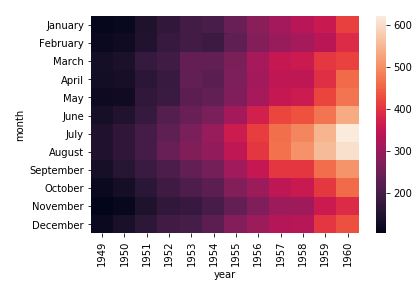
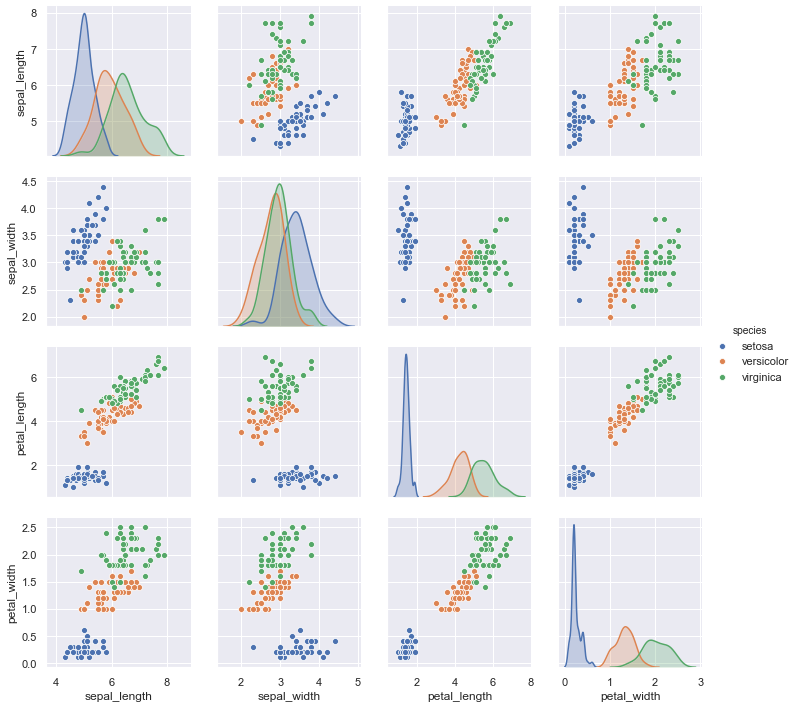
そして後者に関しては、ポイント②で扱ったirisのフリーデータを元に記載します。コードとしては以下のみ。
#分析の軸を考える(仮説づくり)時に使う。
import matplotlib.pyplot as plt
import seaborn as sns
df = sns.load_dataset("iris")
sns.pairplot(df, hue="species", size=2.5)
plt.show()
前者のヒートマップはエクセルでも表の可視化機能として存在していて身近です。好きな色にしたりすることで、クロス集計結果を”なんかそれっぽくすること”が出来ます。報告時には重宝したい手法です。
後者は分析の視点でどの仮説が有力かをあぶりだす分析の分析作成過程で使うような分析です。これは、どちらかというと詳しい人向けの分析、もしくは”分析やってるよ風に魅せる”時に戦略的に使うべきかと思っております。(本質的ではないですが)
データ分析の報告時に考えるべきこと

上記で、手法を記載しましたが、先にも述べた通り業務でデータ分析をする際に軽視されながらも実は非常に重要な視点が
ということです。これは研究室にいた時とビジネスをしている時とで180度違うと思います。個人的にはどちらも変だなと思うことがありましたが、極端な話を言うと以下のような視点が意識されます。
▽研究室での報告時
→とにかく数字の精度と新規性(複雑で良い)。論文を通すにも如何に高度で複雑なことをやっているかをプレゼンできないと審査が通らない印象。
▽ビジネスでの報告時
→とにかく現業へのインパクトとシンプルさ。パッと見た時にお金になるのかならないのか、3秒で誰もが理解できるプレゼンでないと通らない印象(精度はどうでもいい)。
そのため、ビジネスの場合はクロス集計で傾向つかんで、それっぽくパワポをまとめるのが一番フィット感がある気がします。
ただ、その上で、分析結果やプロセスに深く突っ込んで質問された場合のみ、上記を組み合わせ、訴求したいポイント(重要な仮説)を根拠をもって語る必要があるのかなと思います。(分かりやすく視覚化した前提で)
まとめ
今回は分析結果の視覚化の方法についてまとめました。ポイントは以下の3点です。
- 視覚化の必要性とは?
▷報告時は分析内容以上に視覚化が大事 - matplotlab, seabornとは?
▷視覚化に特化したライブラリ - ggpairs, heatmapとは?
▷クロス集計の可視化と仮説作りのお供
視覚化をすると書くと「なんだそれだけか」となりがちですが、実は「意思決定を促進するやり方」と考えると非常に有益な手法だと思います。
そのため、データ分析の学習をすることと合わせて、どのような視覚化をすると”映えするのか”という視点ももちあわせながら勉強していきたいと思います。
ご精読頂きありがとうございました。
m(_ _)m
【参考】Python初心者のお勉強のお供
上記の内容と併せて実務で活かすという視点では下記の参考図書も合わせて確認すると理解が深まります(-_-)
▼オススメの参考書籍(Kindle)▼



【参考】Python初心者が抑えたいポイント集
Python(主にデータ分析・自動化)に関しては
下記に実践したポイントをまとめています。基本的にコピペするだけでそのまま使えます٩( ᐛ )و
業務効率化・自動化においてはGoogle Apps Scriptもセットで学ぶことをオススメ!
こちらもコピペしてすぐに使えます!

PythonとGoogle Apps Scriptどちらを深めようかを迷っていればこちら!














▷分析結果をそれっぽく考察・報告が出来る
(想定場面:意思決定者にデータ分析の報告が必要な状況)
視覚化の必要性とは?
matplotlab, seabornとは?
ggpairs, heatmapとは?