


今回はPythonでの“ディープラーニング”について理解を深めます。
データ分析をしていくと、ディープラーニングという概念を自分でもできないかと思う事が増えます。
ただ、ちょっと調べたけれども敷居が高そう…。
ということでポイントを絞って、下記に整理していきます。
尚、ディープラーニングの統計的な仕組の理解においては下記にポイントを別途まとめます。
今回の論点整理

”ディープラーニング“の使いドコ
ディープラーニングの使いどころは以前も記載した通り画像処理などの領域です。
今回は下記のようなデータ(数字の”4″)を読み込んで傾向を出す・予測する形を構築します。
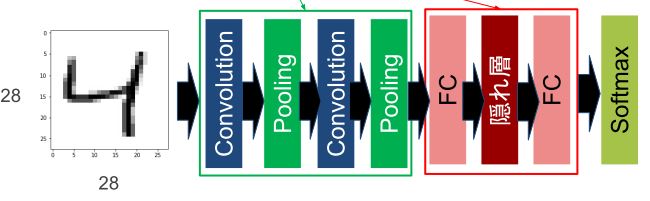
ディープラーニングは雰囲気からして難解を極める領域かとおもいますが、分解して考えるとベース部分はそこまで難しい話ではないので、基礎の理論的な部分とセットでご確認頂けると幸いです。
記事を取得できませんでした。記事IDをご確認ください。
具体的な想定場面
今回の想定は以下の通りです。
このような時、「ディープラーニング」という考え方が使えるのだと思います。
今回の抑えドコ
そこで、今回は上記を実現する手順について下記に備忘録的にまとめたいと思います。
- 今回の焦点
▷ディープラーニングに関して
(想定場面:画像データを使って分類わけのアルゴリズムを考えたい) - ポイント
▷全体のネットワーク構築
▷CNNの書き方
▷画像認識のタスク
順に触れます。
”ディープラーニング”理解のポイント

ポイント① ネットワーク構築の全体像
まず、プログラミング部に触れる前に抑えておきたいのが、ディープラーニングの仕組です。下記を確認頂くのが良いかと思います。
記事を取得できませんでした。記事IDをご確認ください。
上記でも触れましたがCNNという考え方は、画像処理を考える際は当たり前のように使われたりします。
ではまずこれは何なのか。
CNN=Neural NetworkにConvolution(畳み込み)を追加したもの
上記のリンクでも話した通り一言でいえば”読み込んだデータをぼやかす”的な意味合いの処理を行います。
つまり、画像データを数値化し、そのデータをぼやかしまくってそれっぽい特徴を抽出する作業を行います。
全体の流れと設定すべきプログラムの位置づけとしては以下の通り
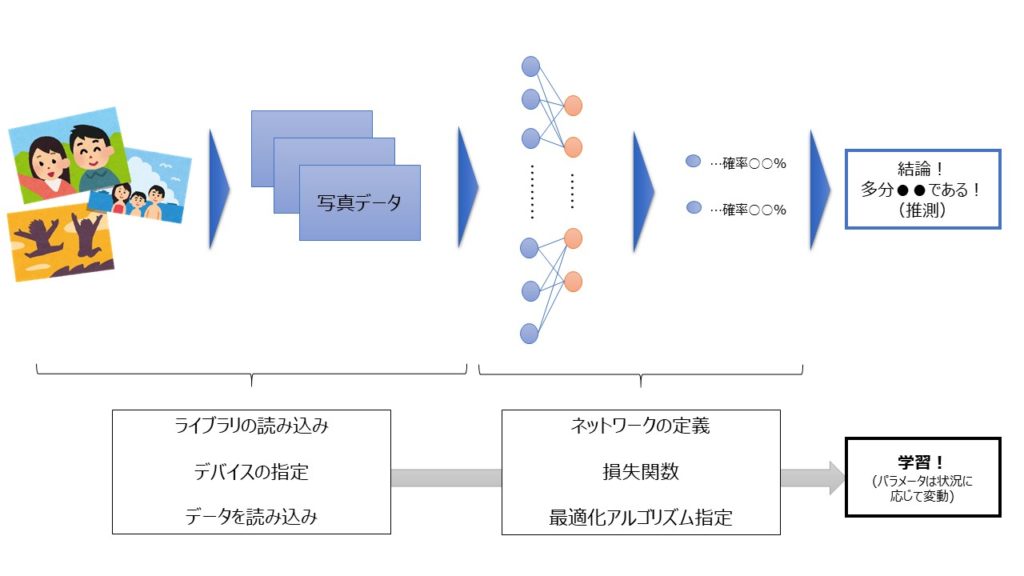
その上で、これを左から順にプログラムにおとしていきます。
- ライブラリの読み込み
- デバイスの指定
- データを読み込み
- ネットワークの定義
- 損失関数
- 最適化アルゴリズムの指定
- 学習
上の順に則して、順にふれていきます。
ポイント②プログラミングの流れ
上記の7つのステップで分けて考えます。
①ライブラリの読み込み
まず、この手の分析をする際の代表格のライブラリは下記3つです。
- TensorFlow
▷ Google製の機械学習フレームワークで最もポピュラーなフレー
ムワークのひとつ
▷ 2019年にTensorFlow2.0が出たので要注目 - Keras
▷Scikit-learnのように簡単にディープラーニングを実行できる高水
準ライブラリ - PyTorch
▷人気急上昇中の機械学習ライブラリで比較的書きやすいと言わ
れる
その中でも今回は、とっつきやすいといわれるPyTorchを扱います。コードは以下の通り。
import torch
from torch import nn
from torch imoport optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, TenesorDataset②デバイスの指定
また、PyTorchではcudaという概念も活用できうる。
cubaとは何かという点はこちら、簡単にいうとGPU(画像用半導体チップ)の計算が出来る環境です。
そこで、もしcudaが使用できるマシンであればTrue、そうでなければFalseを返します。コードは以下の通り。
if torch.cuba.is_available():
device = 'cuba'
else:
device = 'cpu'
print(device)③データを読み込み
学習データとテストデータに分けていきます。具体的にはTensorDatasetとDataLoaderを使います。
コードは以下の通り
X_train, X_test, y_train, y_test = train__test_split(
X, y, test_size=0.3, random_state=1234)
#torch.tensorでNumpyの配列からtensor型にデータ変換
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train, dtype=torch.int64)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test, dtype=torch.int64)
#dataset, loaderをセット
train_dataset = TensorDataset(X_train_tensor,y_train_tensor)
train_loader= DataLoader(train_dataset, batch_size=50, shuffle=True)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)
test_loader = DataLoader(test_dataset, batch_size=50, shuffle = True)④ネットワークの定義
ネットワークの定義はnn.Sequentialを使って以下の3つを指定します。
- 入出力の次元数
▷入力:最初のnn.Linear()関数の最初の引数
▷出力:最後のnn.Linear()関数の最後の引数 - 隠れ層のニューロン数
▷上記の入出力以外のnn.Linear関数の引数 - 活性化関数
▷nn.ReLU()関数
コードで記載すると以下の通り
net = nn.Sequential(
nn.Linear(64,32),
nn.ReLU(),
nn.Linear(32,16),
nn.ReLU(),
nn.Linear(16,10)
)
net⑤損失関数
nn.CrossEntropyLoss()関数で目的関数に交差エントロピー誤差関数を用意します。
これはシンプルに定義だけ
loss_func =nn.CrossEntropyLoss()ちなみに他にもこのような関数
- nn.BCEWithLogitsLoss()
▷2クラス分類交差エントロピー誤差関数 - nn.CrossEntropyLoss()
▷多クラス交差エントロピー誤差関数 - nn.MSELoss()
▷回帰問題平均二乗誤差関数 - nn.L1Loss()
▷回帰問題平均絶対誤差関数
⑥最適化アルゴリズムの指定
あとはパラメーターを初期化し、最適化アルゴリズムを指定すれば準備完了です。
コードは以下の通り
optimizer = optim.SGD(net.parameters(), lr=0.1)ちなみに…SGD以外にもAdam,AdaDelta,AdaGradというものもあります。
⑦学習
そして最後に上記を加味して学習します。関数trainingが必要な変数を辞書型でまとめます。
コードは以下の通り
param = {
'trainloader':train_loader,
'valloader':test_loader,
'net':net,
'optimizer':optimizer,
'lossfunc':loss_func,
'epochs':15,
'device':device
}①~⑥の定義したものを辞書型でパラメータセットをすることで学習がはじまります。
net, train_loss_track, test_loss_track = training(**param)以上を元に、training関数を定義して実行すれば処理が回ります。
ポイント③CNN構築の基本と汎用ネットワーク
上記、CNNにおいて具体的なイメージが沸かないとピンとこないと思うので、ポイント①ポイント②の視点を元にネットワークを定義します。
例えばこの4という画像を読み込んでいくネットワークの定義を想定します。
- Convolution(畳み込み)
▷指定したベクトルを元に意図した形でぼやかす - Pooling(ぼやかし)
▷決まった範囲・法則(平均値など)をとってぼやかす - FC(全結合)
▷画像をフラットにしてニューラルネットにすること - 隠れ層(Relu)
▷活性化関数を元に勾配(影響)を算出 - Softmax
▷出てきた数値からカテゴリと紐づけ・分類わけ
コードにすると以下のような形になります。
net = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=28, kernel_size=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=28, out_channels=32, kernel_size=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
Flatten(),
nn.Linear(1152,100),
nn.ReLU(),
nn.Linear(100,10)
)これが基本形になるわけですが、実際の読み込みを考えるともっともっと複雑な式になります。
つまり、covolution等の処理が信じられない程くりかえさないといけないわけです。
ただ、毎回定義するのは面倒を極めるので、実はプリセットされたものがあるのでそちらのネットワーク(移転学習)を使うのが賢明です。
代表格は以下の通り
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
これらの詳細な特徴はそれぞれググってみればよいと思います。
上記の基本系を理解した上で、上記が活用できればほぼほぼ自分で回せるようになるはずです。
まとめ
上記を活用する際に、理解しておくべきポイントは以下3点
- ポイント①:ネットワーク構築の全体像
▷現実世界に照らし合わせて分析ステップを分ける - ポイント②:プログラム作成の流れ
▷7つのステップに合わせてコードを考える - ポイント③:CNN構築の基本と汎用ネットワーク
▷基本的な書き方を踏まえ移転学習を利用する
ここまで分解して理解ができると、いきなり使いこなせないにしても、何を試しに学んで勉強すればいいのかが分かります。
また、何よりも、今まで意味不明であったディープラーニングの領域の参考書やブログで記載されている意味は理解できるようになると思います。
今後は自主勉強として上記を学ぶ一方で、業務でも出来る事・できないことはしっかりと理解した上で話を勧めたいと思います。
ご精読頂きありがとうございました。
m(_ _)m
【参考】Python初心者のお勉強のお供
上記の内容と併せて実務で活かすという視点では下記の参考図書も合わせて確認すると理解が深まります(-_-)
▼オススメの参考書籍(Kindle)▼



【参考】Python初心者が押さえたいポイント集
Python(主にデータ分析・自動化)に関しては
下記に実践したポイントをまとめています。基本的にコピペするだけでそのまま使えます٩( ᐛ )و

業務効率化・自動化においてはGoogle Apps Scriptもセットで学ぶことをオススメ!
こちらもコピペしてすぐに使えます!

PythonとGoogle Apps Scriptどちらを深めようかを迷っていればこちら!














想定:自分は統計をかじっているパン屋の店主、店舗のオペレーションを合理化するための新システム案を模索中
状況:パン購入時にAIを使ったカメラでの写真データを元に自動判定して価格を出すシステムを作って入力の手間を省けないかを検討している。
意図:上記はどういうロジックで実装すればいいかアルゴリズムエンジンを考えたい。