






今回は“自然言語処理”について理解を深めます。
「自然言語処理」とは、大量のテキストデータから、有益な情報を取り出す分析のことを総称したものです。
言い換えるとテキストマイニングともいいますが、ようは文字情報分析です。
今やウェブページやTwitterなど色々なところにデジタルのテキスト情報があり、それと併せてフリーソフトも出て言います。
ただ、扱うにあたり仕組の部分が理解できないと応用ができないので、この裏の仕組について整理します。
データサイエンスを網羅的にコスパ良く実践的に学びたい時はこちらもオススメ!
>>データミックス使って感じたメリット・デメリット
今回の論点整理

”自然言語処理“の使いドコ
今回の自然言語処理で出来ることとしては以下のようなものです。
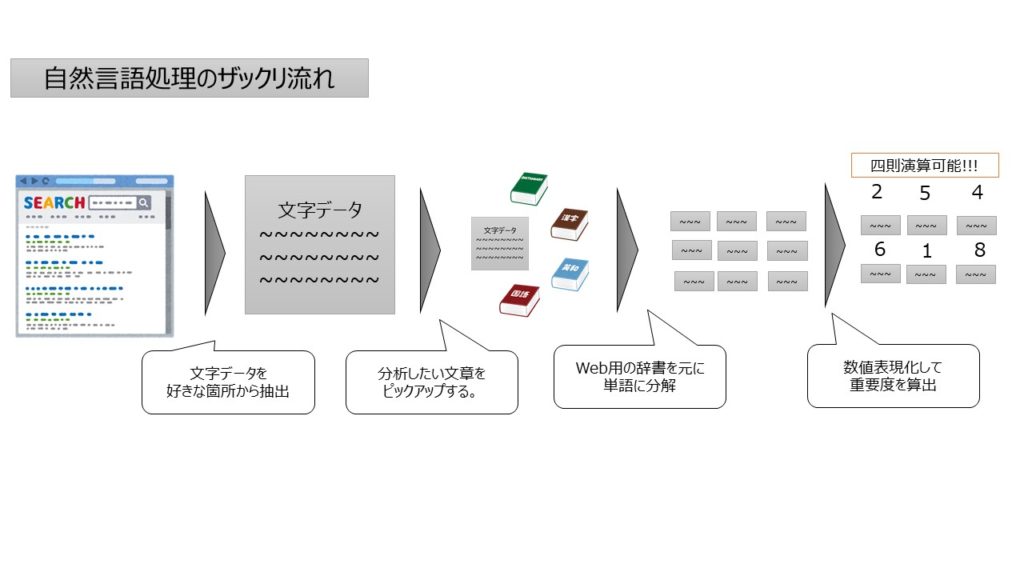
超ざっくりいうと、文字/文章分析であり、一般的にテキストマイニングと言われる領域です。
この領域の一番のポイントはこの文字情報(自然言語)を数字変換して考えるという点です。
個人的にこの分析を見た時「ぇ、定性情報でそんなことできちゃうの!?」という驚きを持ちましたが、実際できてしまうのだから仕方ないです。
そこで、今回はこの定性情報を定量分析がなぜできるのか?という視点にたち、使い所だけけでなく、仕組みや手法の成り立ちについて整理していきたいと思います。
具体的な想定場面
今回の手法は以下のような場面などで使えうると思います。
想定:商品開発部門で現商品を改善するための定性評価や声といったまとまったエビデンスが欲しい
状況:web上やtwitter上のテキストデータなどのオープンデータでマーケティングしたい
意図:上記API開放されているデータを元に、テキストマイニングを用いてうまいこと分析する
このような時、「自然言語処理」という考え方が使えると思います。この領域はプログラム組む以前にフリーソフトも多くあるので試してみることで感覚的に理解できます。
ただ、この手法の背景で動く処理がどうなっているのかを理解しないと応用がきかないので、以下ではこの知識を使う際に思い出すべき点を、後で振り返れるようにポイントを絞って備忘録としてまとめます。
今回の抑えドコ
そこで、今回は上記を実現する手順について下記に備忘録的にまとめたいと思います。
- 今回の焦点
▷自然言語処理に関して
(想定場面:大量の”文字データ”を元に傾向をつかむ必要がある場合) - ポイント
▷辞書とツールとは
▷数値表現/補正
▷単語の演算をする
”自然言語処理”理解のポイント

ポイント① 辞書とツールとは
まずテキストを分析するのに対して、単語レベルで何がどれほどあるのかを分解する作業をします。工程は2つ。照合と分解です。
まず前者の照合を実現するための方法が辞書というものです。
イメージとしてはウェブ上の広辞苑的なものであり、それに照らし合わせて単語を特定して抜き出す作業をしています。
ちなみにこの辞書も種類があり、ウェブ上のスラングに強いものとなど色々あるようです。
そして、後者を実現する考え方が形態素分析という手法であり、それをプログラムで実現するものがツールというものです。
ツールも辞書同様に複数のやり方があり、計算スピードや手法が若干変わるようです。例えば以下のようなものがあります。
- Janome
▷Pythonで書かれた辞書内包の形態素解析ツール - Mecab
▷高性能・高速で活用事例も多い - Sudachi
▷java製で検索システムとの相性がよい

感覚的にはMecabが主流で、pythonならjanome等を使っておけば無難といった感じですかね。
ポイント②数値表現/補正とは
上記の辞書とツールを使うと結果的には単語にわかれます。それを今度は行列式として“数列化”します。
(個人的に定性情報を定量化しようとするこの発想が天才(変態)だなと思いました)
数列にすることで、色々の特徴や関係性を分析したりができるようになります。
ここで、文章の数列を作るわけですが、前提条件として、文章の特徴を考えると少し制約をかける必要があります。
例えば、とある文章でキーワードはどれかを考えると、繰り返しでる単語が重要かといわれるとそうでもないケースがあります。
むしろ、ポイントポイントでちょっとだけでてくるキーワードなどが重要度が高いのでは?という考え方ができます。
ここからは色々と分析者のやり方次第ですが、上記の仮定にたつと、その重要度を以下のような形で指標かしたりすることもできます。
例えばTFーIFDという正規化の表現の式があります。
※TF= 文書dの単語tの出現回数/文書dのすべての単語の出現回数の和
※IDF(重要度)=log(文書総数N/単語tを含む文書数DF)
これは、なんかパッと見、難しそうに見えますが、よくよく読み解いてみるとかなりシンプルです。
例えば下記の例文で考えるとイメージがわきます。
- 私は火曜日がスキ
- 来週の月曜日は私の誕生日
- 私は月曜日が気が重い
- 私は今週、火曜日と水曜日が会議
この場合以下のようになります。
- 文章総数N:4(4つの文章)
- 文書d:①②③④
- 単語t:私、月曜、火曜、スキ、会議、来週、誕生日等
- 単語tを含む文書数DF:「t=私」の場合はDF=4(全てにある)
この考えに乗っ取って英単語に数字をいれていけばいいだけです。
上記の場合「私」という単語は全てにでてくるため重要度は低いが、「会議」などは重要度が高くなってきます。
ポイント③ 単語の演算をする。word2vecとは
上記のように、数字化が出来たらあとは機械学習の考え方です。
クラスタリングするのか、ロジスティック回帰で単語の重要度を定量化するのか、似たものを炙り出すのか、色々やり方はあります。
その中で更に、この考えを応用して単語や文章レベルで演算をするという革新的な手法が提案されます。
それがword2vecという領域です。例えばこんな感じ
確かに言われてみれば、王様から男性要素抜いて、女性用そいれたら確かに王女だろうな…とは思います。。
つまり、感覚的な文字の足し算引き算を実際の数字で割り出して表現して演算可能という驚きの方法です。
(これはめちゃくちゃ変態的…)
これは上記のそれぞれの単語をベクトル化した数値を割り出して演算可能にします。下記のサイトが非常に分かりやすく解説されていました。
▪️参考リンク:word2vecの考え方について(外部リンクに飛びます)
そのため、それぞれのベクトルを予測するために学習するための大量の文章データが多くないと精度がさがります。また、大まかにはモデルは2つあります。
- CBOW(Continueous Bag-of-Word Model)
- Skip-gram
詳細が気になればググってみてください。
前者だけ軽くふれておきますと、ある単語とある単語のベクトルを割り出し、そこから周辺単語をニューラルネットワークを介して単語の間にあるべき単語などを予測するモデルです。
■参考リンク:word2vecを理解する(外部リンクに飛びます)
そのため、手法としてはディープラーニングで記載した内容が応用される形になっています。

まとめ
以上、自然言語処理は文字情報を元に変態的な発想で定性情報を定量化する手法でした。
ただ、仕組みが分かればできる範囲の幅もイメージができますし、数字に縛られる必要がないため拡張性がかなり期待できる手法だと思います。
抑えておきたい理解すべきポイントは以下3点
- ポイント①:辞書とツールとは
▷いい感じに分解してくれるものがある。とりあえずMecabとJanomeあたりを押さえておけばOK - ポイント②:数値表現/補正
▷一見難しそうな式で数値表現化するが、具体例で考えるとさほどむずくない - ポイント③:単語の演算をする
▷word2vecという変態的な考え方が提唱されており結果的に文章の四則演算が可能。ディープラーニング的な考えに基づく。
この領域の仕組みを理解できると分析用のデータはネットやSNS上にウジャウジャあるので好き勝手に色々と分析ができると思います!
まずは、Twitterの情報など、そこらじゅうにまとまった情報はあるのでそれらをうまく使って、この考えで応用して自由研究していきたいと思います!
ご精読頂きありがとうございました!
m(_ _)m
その他、統計基礎のお勉強のお供
上記の内容と併せて実務で活かすという視点では下記の参考図書も合わせて確認すると理解が深まります(-_-)



その他、統計初学者が抑えておきたい理解ポイント
実務での応用を考えると下記のポイントを抑えると実務につながりやすいと思うので合わせてご参照下さい(‘ω’)ノ
【統計基礎】データサイエンスにおける確率分布(ポアソン分布、正規分布等)とは
【統計基礎】分類問題における決定木やランダムフォレストの仕組とは
【統計基礎】クラスタリングにおけるk-meansやエルボーメソッドとは
【統計基礎】分析結果やモデル精度の解釈(決定係数, AUC, 混合行列等)とは
【統計基礎】ディープラーニング, 画像処理(プーリング等)とは
【統計基礎】自然言語処理、テキストマイニング、word2vecとは
【統計基礎】データサイエンスの知識整理 / AI, 機械学習, 深層学習の位置づけ
【統計基礎】経営に”データサイエンス風な報告”を求められた際の留意点
データサイエンスを網羅的にコスパ良く実践的に学びたい時はこちらもオススメ!
>>データミックス使って感じたメリット・デメリット








コメント