


今回はPythonによる”回帰分析のやり方”について言及します。
回帰分析や分類問題は、データ分析による予測の基礎の基礎です。
Pythonではこれらの分析はSklearnというライブラリでほとんどが出来てしまいます。
そのため今回はライブラリの使い方として”回帰分析”を例にプログラム例を示します。
尚、裏でどのような仕組みがなされているのか、といった統計的な理解ポイントは下記にまとめております。

今回の論点整理

今回のアウトプット
下記のようにデータを読み込み、機械学習の専用ライブラリを通して計算して結果を可視化します。
今回は、あまり深く踏み込まずに、簡単な使い方だけサラッと触れていきます。あくまで今回は
ということをまずは前提にやっています。pythonはライブラリが多数用意されているので一つ分析の流れが分かれば後はさほど難しくないです。
今回の抑えドコ
そこで、今回は上記を実現する手順について下記に備忘録的にまとめたいと思います。
- 今回の焦点
▷ライブラリを使って機械学習の手法を使える
(想定場面:変数の多いデータセットの分析が必要な場合) - ポイント
▷機械学習とSklearn
▷回帰分析とは?
▷検証視点とは?
順に触れていきます。
今回のポイント

①機械学習とSklearn
まずは抑えるべき概念とライブラリを超ザックリと触れます。
まず、機械学習とはざっくりといえば、単純集計やクロス集計では出来ない高度な分析ができるもの。と捉えればよいと思います。(また今後まとめますが)
具体的な業務で考えた場合は、以下のようなことを言われたら利用する価値があるかなと思います。
- 「数ある要因の中でどれが一番効いてるの」
- 「相関関係じゃなくて因果関係示せないの」
- 「何等か予測とかできないの」
そして、Sklearnとは上記の声に応えるべく、サクッと高度な計算ができるように各種数式などをまとめたライブラリになります。
②回帰分析とは
さて、次は実際に分析を試してみようと思います。ここでは回帰分析を使います。
これまた、超ザックリいうと、「どの要因がどの程度影響しているか見る分析」とでも押さえておけばよいと思います。(これまた、どこかでまとめます。)
例えば、コンビニで売られている商品の売り上げ影響要因を考えた時に以下がどれほどなのかを機械が算出してくれます。
- 商品の価格
- ライバル店の価格
- その日の天気
- 商品のブランド
- 商品の内容量
- パッケージの色
- 置かれている棚の位置
- 周辺のイベント
- 買われている顧客層
つまり、具体的な分析を想定すると、変数が3個以上あって人間の頭では到底判断するのが無理なものでも、そこを機械が求める値に合わせてぐるぐる数式を回転させながら計算してくれるような類です。
③検証視点とは
ここでは上記の回帰分析(重回帰)を実際にコードにいれて検証視点を考えます。今回も、前回同様、プリセットされているフリーデータ(ボストンの住宅価格データ)を使います。
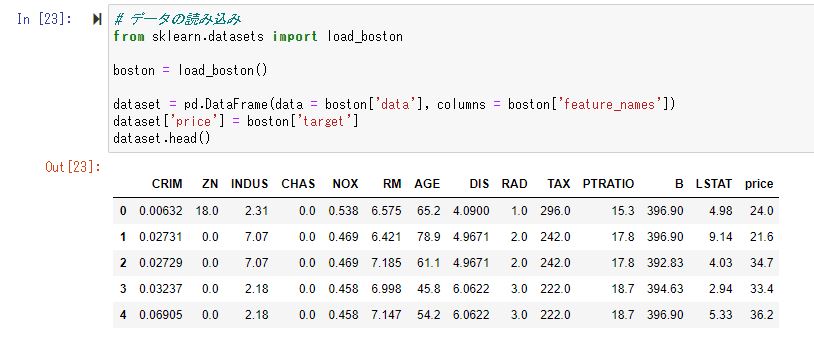
# データの読み込み
from sklearn.datasets import load_boston
boston = load_boston()
dataset = pd.DataFrame(data = boston['data'], columns = boston['feature_names'])
dataset['price'] = boston['target']
dataset.head()まずはデータを読み込み、求めたい値(目的変数)を価格(price)に設定します。そうすると以下のような値になると思います。
その後にこのデータを使って回帰分析の数式を読み込み、分析データをセットします。
# sklearn.linear_model.LinearRegression クラスを読み込み
from sklearn import linear_model
clf = linear_model.LinearRegression()
# 目的変数を指定
Y = dataset['price'].as_matrix()
# 説明変数にを設定
dataset2 = dataset.drop("price", axis=1)
X = dataset2.as_matrix()数式の読み込みとデータのセットはこれだけ。あとはこの高度な分析を実施します。
# 予測モデルを作成
clf.fit(X, Y)
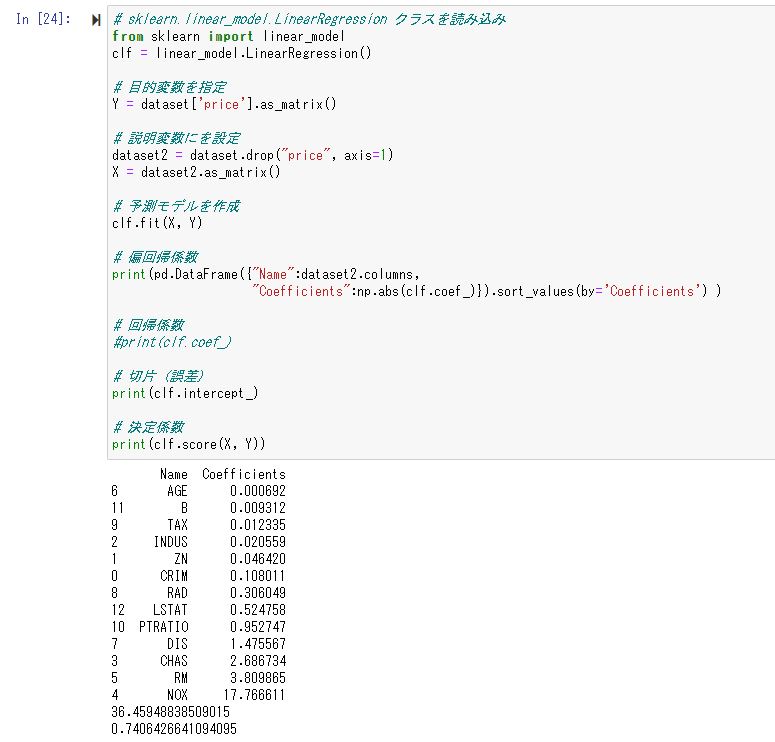
# 偏回帰係数
print(pd.DataFrame({"Name":dataset2.columns,
"Coefficients":np.abs(clf.coef_)}).sort_values(by='Coefficients') )
# 回帰係数
#print(clf.coef_)
# 切片 (誤差)
print(clf.intercept_)
# 決定係数
print(clf.score(X, Y))分析自体もこれだけ実質の分析箇所はclf.fit()で終了です。結果はこのような形です。
あとはこの回帰係数の解釈ですが、基本的には影響度合いがどれくらいかを加味して数字通りの影響度があるとざっくり傾向を読めばOKです。
また、一番下の数字は決定係数と呼び、これらの変数全部でどれくらいを説明しきれているかを100%中何%かを示します。100ならいいというわけではないですが、一旦は高い程よいものだと捉えておけばよいと思います。
そして上記を踏まえ、じゃぁ一つ一つの変数をもう少し詳細に影響度合いを見たいとなった時には、以下のようにXの値を一つの数字に指定しなおし、かつ2軸の視覚化をすると分かりやすいです。
# matplotlib パッケージを読み込み
import matplotlib.pyplot as plt
#2軸で分析する変数を指定
Y = dataset['price'].as_matrix()
X = dataset.loc[:, ['RM']].as_matrix()
# 予測モデルを作成
clf.fit(X, Y)
# 回帰係数
print(clf.coef_)
# 散布図
plt.scatter(X, Y)
# 回帰直線
plt.plot(X, clf.predict(X))
# 決定係数
print(clf.score(X, Y))今回の分析(単回帰)ではX(RM)とY(Price)それぞれ一つの値のため散布図など直感的に分かる図にすることが可能です。結果は以下の通り。

回帰係数と決定係数は上記と同じ見方をすればよく、散布図と近似直線を引いてどのような関係性かを視覚的にわかるようになっています。
上記から、実際のデータを使いましたが、注目するべきは以下の3点です。
- 回帰係数の影響度合い
- 決定係数での説明力
- 散布図・グラフでの視覚化
まとめ
今回の学習のポイントは以下の通りでした。
- 機械学習とSklearn
▷人間ではわからない因果等の関係性を機械が数値化してくれる - 回帰分析とは?
▷機械学習の手法の一つで、多くの影響要因を定量化する - 検証視点とは?
▷回帰係数、決定係数、視覚化を意識
高度なことをするにも関わらず、やりたいこともやるべきことも実はシンプルです。それっぽい結果を算出することは誰でも簡単にできます。ただ、外してはいけないのが実務で使えるか?という視点だと思います。
そのため、まずは実際の実務データ(エクセル等)を読み込み、何がどのように影響しているかを実際に自分の手で動かして解釈するところから始めるのが良いかと思います。
身の回りのデータで自分の持つ知識を元に仮説を検証できると、難しい…というよりは面白い!という感覚になるので、上達するためにはこれの積み重ねなのだろうと思います。
ご精読頂きありがとうございました。
m(_ _)m
【参考】Python初心者のお勉強のお供
上記の内容と併せて実務で活かすという視点では下記の参考図書も合わせて確認すると理解が深まります(-_-)
▼オススメの参考書籍(Kindle)▼



【参考】Python初心者が抑えたいポイント集
Python(主にデータ分析・自動化)に関しては
下記に実践したポイントをまとめています。基本的にコピペするだけでそのまま使えます٩( ᐛ )و

業務効率化・自動化においてはGoogle Apps Scriptもセットで学ぶことをオススメ!
こちらもコピペしてすぐに使えます!

PythonとGoogle Apps Scriptどちらを深めようかを迷っていればこちら!















Pythonを時短で基礎から応用まで一気に学びたい時はこちらもオススメ!
>>【Python】TechAcademyを実際に使ってみて学べたこと